
Much has been written about struggles of deploying machine learning projects to production. As with many burgeoning fields and disciplines, we don’t yet have a shared canonical infrastructure stack or best practices for developing and deploying data-intensive applications. This is both frustrating for companies that would prefer making ML an ordinary, fuss-free value-generating function like software engineering, as well as exciting for vendors who see the opportunity to create buzz around a new category of enterprise software.
The new category is often called MLOps. While there isn’t an authoritative definition for the term, it shares its ethos with its predecessor, the DevOps movement in software engineering: by adopting well-defined processes, modern tooling, and automated workflows, we can streamline the process of moving from development to robust production deployments. This approach has worked well for software development, so it is reasonable to assume that it could address struggles related to deploying machine learning in production too.

Learn faster. Dig deeper. See farther.
However, the concept is quite abstract. Just introducing a new term like MLOps doesn’t solve anything by itself, rather, it just adds to the confusion. In this article, we want to dig deeper into the fundamentals of machine learning as an engineering discipline and outline answers to key questions:
- Why does ML need special treatment in the first place? Can’t we just fold it into existing DevOps best practices?
- What does a modern technology stack for streamlined ML processes look like?
- How can you start applying the stack in practice today?
Why: Data Makes It Different
All ML projects are software projects. If you peek under the hood of an ML-powered application, these days you will often find a repository of Python code. If you ask an engineer to show how they operate the application in production, they will likely show containers and operational dashboards—not unlike any other software service.
Since software engineers manage to build ordinary software without experiencing as much pain as their counterparts in the ML department, it begs the question: should we just start treating ML projects as software engineering projects as usual, maybe educating ML practitioners about the existing best practices?
Let’s start by considering the job of a non-ML software engineer: writing traditional software deals with well-defined, narrowly-scoped inputs, which the engineer can exhaustively and cleanly model in the code. In effect, the engineer designs and builds the world wherein the software operates.
In contrast, a defining feature of ML-powered applications is that they are directly exposed to a large amount of messy, real-world data which is too complex to be understood and modeled by hand.
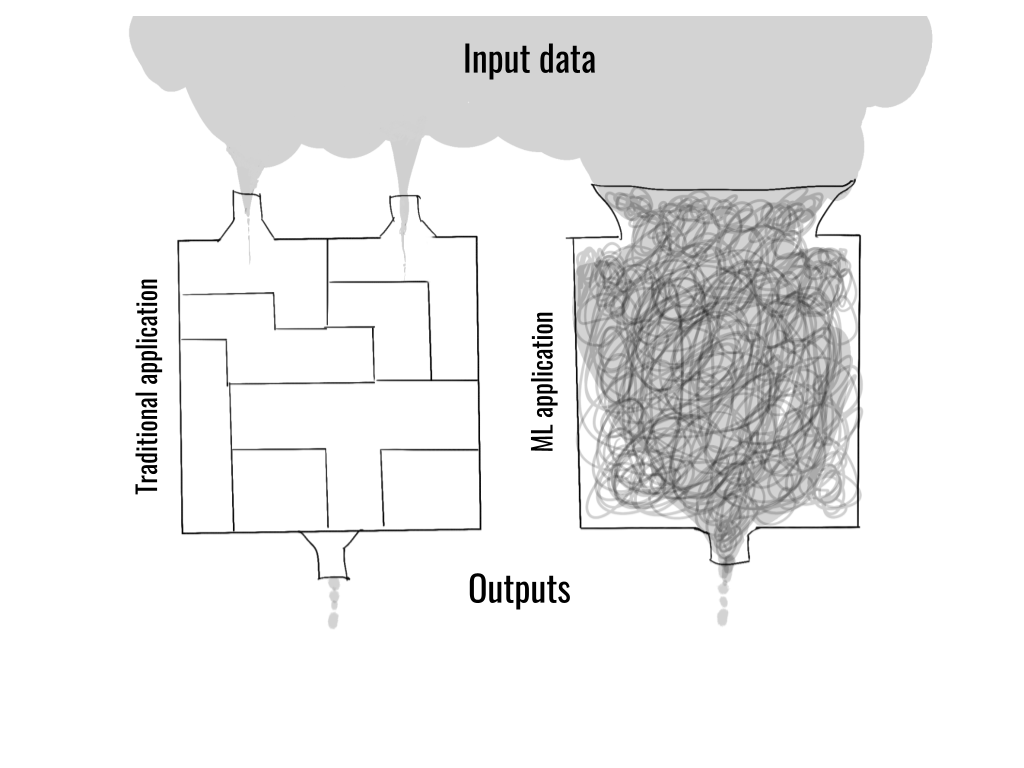
This characteristic makes ML applications fundamentally different from traditional software. It has far-reaching implications as to how such applications should be developed and by whom:
- ML applications are directly exposed to the constantly changing real world through data, whereas traditional software operates in a simplified, static, abstract world which is directly constructed by the developer.
- ML apps need to be developed through cycles of experimentation: due to the constant exposure to data, we don’t learn the behavior of ML apps through logical reasoning but through empirical observation.
- The skillset and the background of people building the applications gets realigned: while it is still effective to express applications in code, the emphasis shifts to data and experimentation—more akin to empirical science—rather than traditional software engineering.
This approach is not novel. There is a decades-long tradition of data-centric programming: developers who have been using data-centric IDEs, such as RStudio, Matlab, Jupyter Notebooks, or even Excel to model complex real-world phenomena, should find this paradigm familiar. However, these tools have been rather insular environments: they are great for prototyping but lacking when it comes to production use.
To make ML applications production-ready from the beginning, developers must adhere to the same set of standards as all other production-grade software. This introduces further requirements:
- The scale of operations is often two orders of magnitude larger than in the earlier data-centric environments. Not only is data larger, but models—deep learning models in particular—are much larger than before.
- Modern ML applications need to be carefully orchestrated: with the dramatic increase in the complexity of apps, which can require dozens of interconnected steps, developers need better software paradigms, such as first-class DAGs.
- We need robust versioning for data, models, code, and preferably even the internal state of applications—think Git on steroids to answer inevitable questions: What changed? Why did something break? Who did what and when? How do two iterations compare?
- The applications must be integrated to the surrounding business systems so ideas can be tested and validated in the real world in a controlled manner.
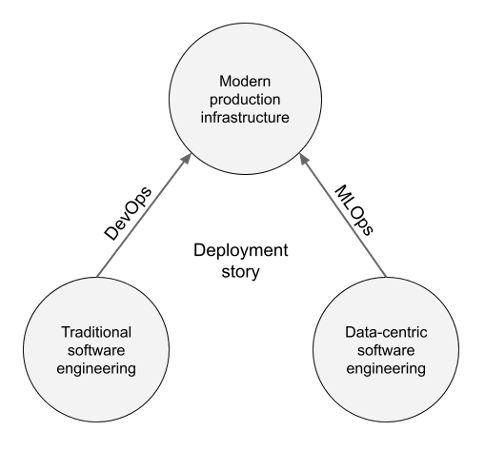
Two important trends collide in these lists. On the one hand we have the long tradition of data-centric programming; on the other hand, we face the needs of modern, large-scale business applications. Either paradigm is insufficient by itself: it would be ill-advised to suggest building a modern ML application in Excel. Similarly, it would be pointless to pretend that a data-intensive application resembles a run-off-the-mill microservice which can be built with the usual software toolchain consisting of, say, GitHub, Docker, and Kubernetes.
We need a new path that allows the results of data-centric programming, models and data science applications in general, to be deployed to modern production infrastructure, similar to how DevOps practices allows traditional software artifacts to be deployed to production continuously and reliably. Crucially, the new path is analogous but not equal to the existing DevOps path.
What: The Modern Stack of ML Infrastructure
What kind of foundation would the modern ML application require? It should combine the best parts of modern production infrastructure to ensure robust deployments, as well as draw inspiration from data-centric programming to maximize productivity.
While implementation details vary, the major infrastructural layers we’ve seen emerge are relatively uniform across a large number of projects. Let’s now take a tour of the various layers, to begin to map the territory. Along the way, we’ll provide illustrative examples. The intention behind the examples is not to be comprehensive (perhaps a fool’s errand, anyway!), but to reference concrete tooling used today in order to ground what could otherwise be a somewhat abstract exercise.
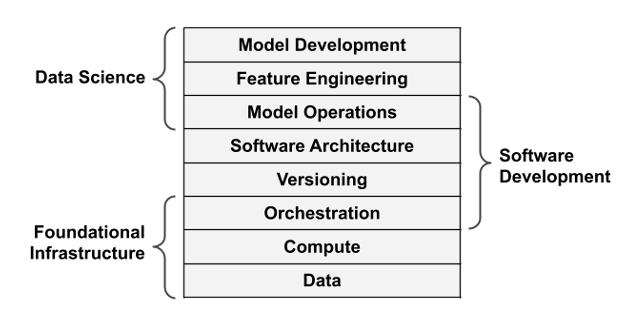
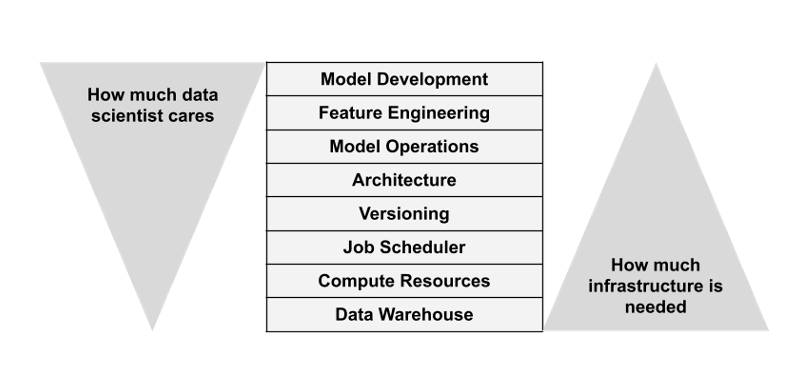
Foundational Infrastructure Layers
Data
Data is at the core of any ML project, so data infrastructure is a foundational concern. ML use cases rarely dictate the master data management solution, so the ML stack needs to integrate with existing data warehouses. Cloud-based data warehouses, such as Snowflake, AWS’ portfolio of databases like RDS, Redshift or Aurora, or an S3-based data lake, are a great match to ML use cases since they tend to be much more scalable than traditional databases, both in terms of the data set sizes as well as query patterns.
Compute
To make data useful, we must be able to conduct large-scale compute easily. Since the needs of data-intensive applications are diverse, it is useful to have a general-purpose compute layer that can handle different types of tasks from IO-heavy data processing to training large models on GPUs. Besides variety, the number of tasks can be high too: imagine a single workflow that trains a separate model for 200 countries in the world, running a hyperparameter search over 100 parameters for each model—the workflow yields 20,000 parallel tasks.
Prior to the cloud, setting up and operating a cluster that can handle workloads like this would have been a major technical challenge. Today, a number of cloud-based, auto-scaling systems are easily available, such as AWS Batch. Kubernetes, a popular choice for general-purpose container orchestration, can be configured to work as a scalable batch compute layer, although the downside of its flexibility is increased complexity. Note that container orchestration for the compute layer is not to be confused with the workflow orchestration layer, which we will cover next.
Orchestration
The nature of computation is structured: we must be able to manage the complexity of applications by structuring them, for example, as a graph or a workflow that is orchestrated.
The workflow orchestrator needs to perform a seemingly simple task: given a workflow or DAG definition, execute the tasks defined by the graph in order using the compute layer. There are countless systems that can perform this task for small DAGs on a single server. However, as the workflow orchestrator plays a key role in ensuring that production workflows execute reliably, it makes sense to use a system that is both scalable and highly available, which leaves us with a few battle-hardened options, for instance: Airflow, a popular open-source workflow orchestrator; Argo, a newer orchestrator that runs natively on Kubernetes, and managed solutions such as Google Cloud Composer and AWS Step Functions.
Software Development Layers
While these three foundational layers, data, compute, and orchestration, are technically all we need to execute ML applications at arbitrary scale, building and operating ML applications directly on top of these components would be like hacking software in assembly language: technically possible but inconvenient and unproductive. To make people productive, we need higher levels of abstraction. Enter the software development layers.
Versioning
ML app and software artifacts exist and evolve in a dynamic environment. To manage the dynamism, we can resort to taking snapshots that represent immutable points in time: of models, of data, of code, and of internal state. For this reason, we require a strong versioning layer.
While Git, GitHub, and other similar tools for software version control work well for code and the usual workflows of software development, they are a bit clunky for tracking all experiments, models, and data. To plug this gap, frameworks like Metaflow or MLFlow provide a custom solution for versioning.
Software Architecture
Next, we need to consider who builds these applications and how. They are often built by data scientists who are not software engineers or computer science majors by training. Arguably, high-level programming languages like Python are the most expressive and efficient ways that humankind has conceived to formally define complex processes. It is hard to imagine a better way to express non-trivial business logic and convert mathematical concepts into an executable form.
However, not all Python code is equal. Python written in Jupyter notebooks following the tradition of data-centric programming is very different from Python used to implement a scalable web server. To make the data scientists maximally productive, we want to provide supporting software architecture in terms of APIs and libraries that allow them to focus on data, not on the machines.
Data Science Layers
With these five layers, we can present a highly productive, data-centric software interface that enables iterative development of large-scale data-intensive applications. However, none of these layers help with modeling and optimization. We cannot expect data scientists to write modeling frameworks like PyTorch or optimizers like Adam from scratch! Furthermore, there are steps that are needed to go from raw data to features required by models.
Model Operations
When it comes to data science and modeling, we separate three concerns, starting from the most practical progressing towards the most theoretical. Assuming you have a model, how can you use it effectively? Perhaps you want to produce predictions in real-time or as a batch process. No matter what you do, you should monitor the quality of the results. Altogether, we can group these practical concerns in the model operations layer. There are many new tools in this space helping with various aspects of operations, including Seldon for model deployments, Weights and Biases for model monitoring, and TruEra for model explainability.
Feature Engineering
Before you have a model, you have to decide how to feed it with labelled data. Managing the process of converting raw facts to features is a deep topic of its own, potentially involving feature encoders, feature stores, and so on. Producing labels is another, equally deep topic. You want to carefully manage consistency of data between training and predictions, as well as make sure that there’s no leakage of information when models are being trained and tested with historical data. We bucket these questions in the feature engineering layer. There’s an emerging space of ML-focused feature stores such as Tecton or labeling solutions like Scale and Snorkel. Feature stores aim to solve the challenge that many data scientists in an organization require similar data transformations and features for their work and labeling solutions deal with the very real challenges associated with hand labeling datasets.
Model Development
Finally, at the very top of the stack we get to the question of mathematical modeling: What kind of modeling technique to use? What model architecture is most suitable for the task? How to parameterize the model? Fortunately, excellent off-the-shelf libraries like scikit-learn and PyTorch are available to help with model development.
An Overarching Concern: Correctness and Testing
Regardless of the systems we use at each layer of the stack, we want to guarantee the correctness of results. In traditional software engineering we can do this by writing tests: for instance, a unit test can be used to check the behavior of a function with predetermined inputs. Since we know exactly how the function is implemented, we can convince ourselves through inductive reasoning that the function should work correctly, based on the correctness of a unit test.
This process doesn’t work when the function, such as a model, is opaque to us. We must resort to black box testing—testing the behavior of the function with a wide range of inputs. Even worse, sophisticated ML applications can take a huge number of contextual data points as inputs, like the time of day, user’s past behavior, or device type into account, so an accurate test set up may need to become a full-fledged simulator.
Since building an accurate simulator is a highly non-trivial challenge in itself, often it is easier to use a slice of the real-world as a simulator and A/B test the application in production against a known baseline. To make A/B testing possible, all layers of the stack should be be able to run many versions of the application concurrently, so an arbitrary number of production-like deployments can be run simultaneously. This poses a challenge to many infrastructure tools of today, which have been designed for more rigid traditional software in mind. Besides infrastructure, effective A/B testing requires a control plane, a modern experimentation platform, such as StatSig.
How: Wrapping The Stack For Maximum Usability
Imagine choosing a production-grade solution for each layer of the stack: for instance, Snowflake for data, Kubernetes for compute (container orchestration), and Argo for workflow orchestration. While each system does a good job at its own domain, it is not trivial to build a data-intensive application that has cross-cutting concerns touching all the foundational layers. In addition, you have to layer the higher-level concerns from versioning to model development on top of the already complex stack. It is not realistic to ask a data scientist to prototype quickly and deploy to production with confidence using such a contraption. Adding more YAML to cover cracks in the stack is not an adequate solution.
Many data-centric environments of the previous generation, such as Excel and RStudio, really shine at maximizing usability and developer productivity. Optimally, we could wrap the production-grade infrastructure stack inside a developer-oriented user interface. Such an interface should allow the data scientist to focus on concerns that are most relevant for them, namely the topmost layers of stack, while abstracting away the foundational layers.
The combination of a production-grade core and a user-friendly shell makes sure that ML applications can be prototyped rapidly, deployed to production, and brought back to the prototyping environment for continuous improvement. The iteration cycles should be measured in hours or days, not in months.
Over the past five years, a number of such frameworks have started to emerge, both as commercial offerings as well as in open-source.
Metaflow is an open-source framework, originally developed at Netflix, specifically designed to address this concern (disclaimer: one of the authors works on Metaflow): How can we wrap robust production infrastructure in a single coherent, easy-to-use interface for data scientists? Under the hood, Metaflow integrates with best-of-the-breed production infrastructure, such as Kubernetes and AWS Step Functions, while providing a development experience that draws inspiration from data-centric programming, that is, by treating local prototyping as the first-class citizen.
Google’s open-source Kubeflow addresses similar concerns, although with a more engineer-oriented approach. As a commercial product, Databricks provides a managed environment that combines data-centric notebooks with a proprietary production infrastructure. All cloud providers provide commercial solutions as well, such as AWS Sagemaker or Azure ML Studio.
While these solutions, and many less known ones, seem similar on the surface, there are many differences between them. When evaluating solutions, consider focusing on the three key dimensions covered in this article:
- Does the solution provide a delightful user experience for data scientists and ML engineers? There is no fundamental reason why data scientists should accept a worse level of productivity than is achievable with existing data-centric tools.
- Does the solution provide first-class support for rapid iterative development and frictionless A/B testing? It should be easy to take projects quickly from prototype to production and back, so production issues can be reproduced and debugged locally.
- Does the solution integrate with your existing infrastructure, in particular to the foundational data, compute, and orchestration layers? It is not productive to operate ML as an island. When it comes to operating ML in production, it is beneficial to be able to leverage existing production tooling for observability and deployments, for example, as much as possible.
It is safe to say that all existing solutions still have room for improvement. Yet it seems inevitable that over the next five years the whole stack will mature, and the user experience will converge towards and eventually beyond the best data-centric IDEs. Businesses will learn how to create value with ML similar to traditional software engineering and empirical, data-driven development will take its place amongst other ubiquitous software development paradigms.